Predicting Box Office Movie Hype from Cast Popularity (Part 1: Web Scraping)
Part 1: Finding & Scraping the Data Using Selenium & Scrapy

This is the first part of a multi-part series walking through my second project for the Metis Data Science Bootcamp (Project Luther). In this first part, I'll go over the background and the methods used for scraping the data. Read on if your interested in the general scraping process, or in any of the following technologies:
Python / Pandas
Selenium
Scrapy
The full code for this project can be found on my GitHub page.
Defining the Problem

For this project, I wanted to take a look at a specific feature to see if I could predict box office performance of newly released movies. While lots of elements such as critical acclaim, marketing, release season, and competition among movies can have influence on how well a movie does in theaters, I wanted to try to answer one question:
“How much of an impact does the popularity of a movie’s cast members have on its opening weekend box office ticket sales?”
In general, I expected to see some correlation between opening weekend performance and cast popularity. The tough part would be finding a way to quantify the "star power" aspect of a movie. To do this, I needed to find and scrape some online data!
Finding and Scraping the Data
For this project, I tried to limit myself to a single data source - IMDB. I knew that limiting my search to a single website's database would give me a better shot at finding data that I could use together! To start, I noticed that IMDB makes their data available to the public in a downloadable form - Perfect! Even better, this data is updated daily, so I knew it'd be up to date! So I just went ahead and downloaded all of the data, which consisted of the following:
title.basics.tsv.gz - Contains the following information for titles:
- tconst (string) - alphanumeric unique identifier of the title
- titleType (string) – the type/format of the title (e.g. movie, short, tvseries, tvepisode, video, etc)
- primaryTitle (string) – the more popular title / the title used by the filmmakers on promotional materials at the point of release
- originalTitle (string) - original title, in the original language
- isAdult (boolean) - 0: non-adult title; 1: adult title.
- startYear (YYYY) – represents the release year of a title. In the case of TV Series, it is the series start year.
- endYear (YYYY) – TV Series end year. ‘\N’ for all other title types
- runtimeMinutes – primary runtime of the title, in minutes
- genres (string array) – includes up to three genres associated with the title
title.crew.tsv.gz – Contains the director and writer information for all the titles in IMDb. Fields include:
- tconst (string)
- directors (array of nconsts) - director(s) of the given title
- writers (array of nconsts) – writer(s) of the given title
title.episode.tsv.gz – Contains the tv episode information. Fields include:
- tconst (string) - alphanumeric identifier of episode
- parentTconst (string) - alphanumeric identifier of the parent TV Series
- seasonNumber (integer) – season number the episode belongs to
- episodeNumber (integer) – episode number of the tconst in the TV series.
title.principals.tsv.gz – Contains the principal cast/crew for titles
- tconst (string)
- principalCast (array of nconsts) – title’s top-billed cast/crew
title.ratings.tsv.gz – Contains the IMDb rating and votes information for titles
- tconst (string)
- averageRating – weighted average of all the individual user ratings
- numVotes - number of votes the title has received
name.basics.tsv.gz – Contains the following information for names:
- nconst (string) - alphanumeric unique identifier of the name/person
- primaryName (string)– name by which the person is most often credited
- birthYear – in YYYY format
- deathYear – in YYYY format if applicable, else ‘\N’
- primaryProfession (array of strings)– the top-3 professions of the person
- knownForTitles (array of tconsts) – titles the person is known for
Awesome! Now I have way more data than I need! Not that this is the worst thing, obviously, but we'll need to do some filtering. To do this, I decided to use Pandas to import and clean up the data.
Importing and Cleaning in Pandas
So the first thing to do was to import all of the tables to their own Pandas DataFrames. Fair warning, this is a pretty intensive process on your computer's memory, so you may only want to import one at a time if your computer starts hanging up...
title_basics_df = pd.read_csv('Data/title.basics.tsv', sep='\t')
title_cast_df = pd.read_csv('Data/title.principals.tsv', sep='\t')
title_ratings_df = pd.read_csv('Data/title.ratings.tsv', sep='\t')Great! So we've imported our data - now it's time to merge these tables together. However, it may make the process easier if I can filter out what I want from one of these tables first. For this project, I decided to filter my data by the following criteria:
Release year is between 2014 and 2017, inclusive
Title type is 'movie', to avoid bringing in shorts and TV shows
The movie is not an "adult movie," whatever those are...
Movie runtime is at least 80 minutes (I just want to look at feature-length movies - 2 minute shorts aren't going to cut it!)
Genre data is not empty, and also not a documentary
In a Pandas filter mask, it looks something like this:
mask = ((title_basics_df['startYear'] >= 2014) &
(title_basics_df['startYear'] <= 2017) &
(title_basics_df['titleType'] == 'movie') &
(title_basics_df['isAdult'] == 0) &
(title_basics_df['runtimeMinutes'] > 80) &
(title_basics_df['genres'] != '') &
(title_basics_df['genres'] != 'Documentary'))I also had to clean up the data before applying these filters. Some of the columns were unnecessary, while others were not in the right format (like years and runtime minutes), so I created a couple of helper functions to clean these up:
## Helper Functions
def clean_year(y):
# Return year as an integer or 'NaN' if empty
import numpy as np
try:
return int(y)
except:
return np.nan
def clean_genre(y):
# Return only the first genre listed
y = str(y)
if y == '\\N':
return ''
return y.split(',')[0].strip()
title_basics_df.drop('endYear', axis=1, inplace=True)
title_basics_df['startYear'] = title_basics_df['startYear'].apply(clean_year)
title_basics_df['runtimeMinutes'] = title_basics_df['runtimeMinutes'].apply(clean_year)
title_basics_df['genres'] = title_basics_df['genres'].apply(clean_genre)
title_basics_df.dropna(inplace=True, how='any', subset=['startYear', 'runtimeMinutes'])Then we just need to merge the data together,
titles = title_basics_df[mask].merge(title_cast_df, on='tconst')
titles = titles.merge(title_ratings_df, on='tconst')So we've narrowed our dataset down from over 4 million titles to only 17,546 that match our criteria. This will obviously make our scraping process much quicker. Let's pickle this list of title ID's so we don't have to do this cleaning every time:
# Save our data to a "pickle" file, which can be loaded quickly later during our scraping process.
import pickle
with open('my_data.pkl', 'wb') as picklefile:
pickle.dump(titles['tconst'].values, picklefile)Grabbing IMDB Box Office Data Using Scrapy
To pull the box office data from the IMDB website, I used the Python library Scrapy. Scrapy is a framework for extracting web data, and uses a "web spider" to traverse through pages and pull the data of interest. For my spider, I started by loading the pickle file created in the earlier section, and used these title IDs to generate a list of urls to scrape from. This was easy to do, fortunately, since IMDB uses a common format for each movie page:
http://www.imdb.com/title/tt0974015/
where "tt0974015" is the title ID for the latest (at the time of writing) "Justice League" movie, as an example.
Code for the main portion of my spider class is below.
import scrapy
import pickle
class IMDBSpider(scrapy.Spider):
name = 'imdb_spider'
# Use a delay on the scraping to avoid overloading IMDB's servers!
custom_settings = {
"DOWNLOAD_DELAY": 3,
"CONCURRENT_REQUESTS_PER_DOMAIN": 3,
"HTTPCACHE_ENABLED": True
}
# Load the list of title IDs from the pickle file
# created in the previous section
with open("../my_data.pkl", 'rb') as picklefile:
links = list(pickle.load(picklefile))
# Generate the list of urls to scrape (based on title ID)
start_urls = [
'http://www.imdb.com/title/%s/' % l for l in links
]
# Methods go here!On to the method...
Scrapy requires a spider object to have a parser method. This method essentially tells the web scraper what to extract from the page, and also does some basic data processing to ensure the data being pulled out a) actually exists and b) is in a format that will be usable later.
The data is found using "xpaths." For example, suppose we want to extract the title of a movie page. If we inspect the page, we can find the HTML xpath to the title element.
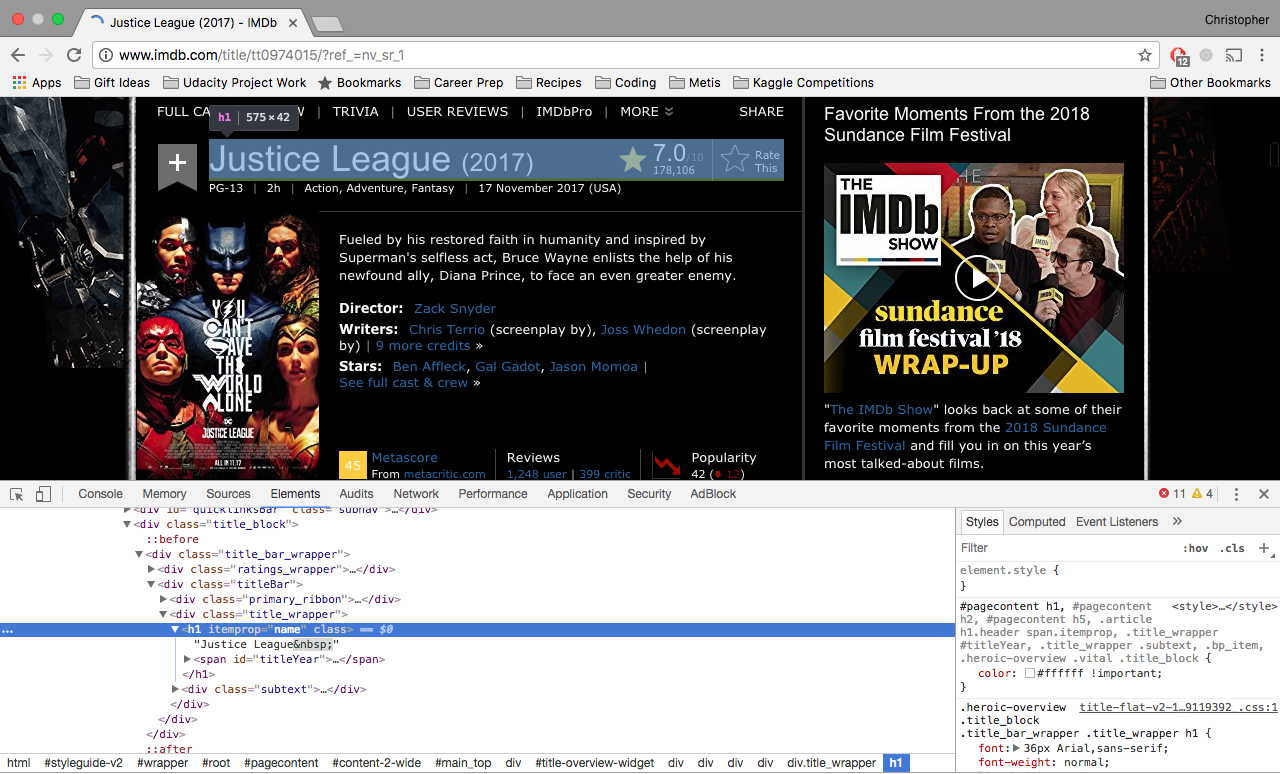
For this example, we know that movie title is located as text within the <h1> header element, and we know an attribute of the element as well. We can set our xpath as the following:
“//h1[@itemprop=”name”]/text()”
Thus, in our parsing code, we would have the following line:
title = response.xpath('//h1[@itemprop="name"]/text()').extract()[0].replace('\xa0','')This code extracts the contained text for the first occurrence of an <h1> tag with itemprop="name". It also does some processing in the same line to remove extraneous characters from the text element ('\xa0').
We repeat a similar method to extract the following data points for each movie page:
Title ID (just pulled from url)
Title (i.e. "Justice League")
Release Date
MPAA Rating
Director Name
Studio Name
Box Office Data (if available)
Budget
Opening Weekend USA Gross
Gross USA
Cumulative Worldwide Gross
Metacritic Score
I should also note that if box office info is not included for a movie title being scraped, the movie will be ignored and not added to this database. Due to the scope of this problem (trying to predict opening weekend box office sales), we will be ignoring films that do not have this info available to the public.
Below is the parse method for scraping these web pages. for each page, if box office data is available, the items are scraped and stored into a python dictionary. This dictionary is then returned back to the object and stored in an external file.
def parse(self, response):
# Extract the links to the individual festival pages
if 'Box Office' in response.xpath('//h3[@class="subheading"]/text()').extract():
title_id = response.url.split('/')[-2]
title = response.xpath('//h1[@itemprop="name"]/text()').extract()[0].replace('\xa0','')
release = response.xpath('//div[@class="subtext"]/a/text()').extract()[0].replace('\n','')
try:
rating = response.xpath('//meta[@itemprop="contentRating"]/@content').extract()[0]
except:
rating = ''
try:
director = response.xpath('//span[@itemprop="director"]/a/span[@itemprop="name"]/text()').extract()[0]
except:
director = ''
try:
studio = response.xpath('//span[@itemprop="creator"][@itemtype="http://schema.org/Organization"]/a/span[@itemprop="name"]/text()').extract()[0]
except:
studio = ''
moneys = response.xpath('//h3[@class="subheading"]')[0].xpath('following-sibling::div/text()').re(r'\$[0-9,]+')
money_labels = response.xpath('//h3[@class="subheading"]')[0].xpath('following-sibling::div/h4/text()').extract()
moneys = [i.replace(',','').replace('$','') for i in moneys]
budget = ''
opening = ''
gross = ''
worldwide_gross = ''
try:
for m, l in zip(moneys, money_labels[:len(moneys)]):
if 'budget' in l.lower():
budget = m
elif 'opening' in l.lower():
opening = m
elif 'worldwide' in l.lower():
worldwide_gross = m
elif 'gross' in l.lower():
gross = m
else:
continue
except:
pass
try:
metacritic_score = response.xpath('//div[@class="titleReviewBarItem"]/a/div/span/text()').extract()[0]
except:
metacritic_score = ''
yield {
'title_id': title_id,
'title': title,
'release': release,
'director': director,
'studio': studio,
'budget': budget,
'opening': opening,
'gross': gross,
'worldwide_gross': worldwide_gross,
'metacritic_score': metacritic_score,
'mpaa_rating': rating
}To run the Scrapy spider, the following command is called at the command line
scrapy crawl imdb_spider -o 'import_data.json'Running this command takes some time, but the web spider scrapes through all of the pages for movie titles stored in our pickle file, and saves the parsed results in json format (to the file named 'import_data.json').
[
{"title_id": "tt0315642", "title": "Wazir", "release": "8 January 2016 (USA)", "director": "Bejoy Nambiar", "studio": "Vinod Chopra Productions", "budget": "", "opening": "586028", "gross": "586028", "worldwide_gross": "", "metacritic_score": "", "mpaa_rating": ""},
{"title_id": "tt0339736", "title": "The Evil Within", "release": "30 August 2017 (Indonesia)", "director": "Andrew Getty", "studio": "Supernova LLC", "budget": "6000000", "opening": "", "gross": "", "worldwide_gross": "", "metacritic_score": "", "mpaa_rating": "NOT RATED"},
{"title_id": "tt0365907", "title": "A Walk Among the Tombstones", "release": "19 September 2014 (USA)", "director": "Scott Frank", "studio": "1984 Private Defense Contractors", "budget": "28000000", "opening": "12758780", "gross": "26307600", "worldwide_gross": "", "metacritic_score": "57", "mpaa_rating": "R"},
{"title_id": "tt0369610", "title": "Jurassic World", "release": "12 June 2015 (USA)", "director": "Colin Trevorrow", "studio": "Universal Pictures", "budget": "150000000", "opening": "208806270", "gross": "652270625", "worldwide_gross": "1670400637", "metacritic_score": "59", "mpaa_rating": "PG-13"},
{"title_id": "tt0376479", "title": "American Pastoral", "release": "21 October 2016 (USA)", "director": "Ewan McGregor", "studio": "Lakeshore Entertainment", "budget": "", "opening": "149038", "gross": "541457", "worldwide_gross": "", "metacritic_score": "43", "mpaa_rating": "R"},
{"title_id": "tt0403935", "title": "Action Jackson", "release": "5 December 2014 (India)", "director": "Prabhudheva", "studio": "Baba Films", "budget": "", "opening": "171795", "gross": "171795", "worldwide_gross": "", "metacritic_score": "", "mpaa_rating": "NOT RATED"},
{"title_id": "tt0420293", "title": "The Stanford Prison Experiment", "release": "17 July 2015 (USA)", "director": "Kyle Patrick Alvarez", "studio": "Coup d'Etat Films", "budget": "", "opening": "37514", "gross": "643557", "worldwide_gross": "", "metacritic_score": "67", "mpaa_rating": "R"},
{"title_id": "tt0435651", "title": "The Giver", "release": "15 August 2014 (USA)", "director": "Phillip Noyce", "studio": "Tonik Productions", "budget": "25000000", "opening": "12305016", "gross": "45089048", "worldwide_gross": "", "metacritic_score": "47", "mpaa_rating": "PG-13"},
...Great! After running this script, we're left with about 6,000 movie titles that have box office data available. This may still be more data than we really need for this project, but I have a feeling we can filter this down a bit more before we start the Selenium scraping...
Importing and Cleaning Up the Scrapy Data
So we have our JSON file of all the data we scraped! Let's load this into a Pandas DataFrame and see what we're working with.
# Load IMDB title scrapy results
# Read json file
import json
import pandas as pd
# Load scrapy json to my_data
with open('imdb_spider/import_20Jan18_5.json', 'r') as f:
my_data = json.load(f)
imdb_info = pd.DataFrame(my_data)
Looks like we need to do a bit more cleaning, since we have some missing data after running our scraping tool. Some films don't post all of their box-office info, which is totally fine, but doesn't make our job of predicting sales any easier. Some empty values aren't a problem, like 'gross' or 'worldwide_gross', because these obviously won't be used to predicting opening weekend sales. However, we need to remove rows that are missing the following data:
Budget
Opening [Weekend Box Office Gross]
MPAA Rating (remove if empty or if it's some obscure rating like 'UNRATED', 'NOT RATED', 'or 'TV-14')
We set up another filter mask like the one below, and then clean up the DataFrame. The cleaning process also includes converting all pricing data from strings to integers, and string dates to datetime objects.
# Filter out only useful data (ignore empty values or infrequent ratings)
imdb_mask = ((imdb_info['budget'] != '') &
(imdb_info['opening'] != '') &
(~imdb_info['mpaa_rating'].isin(['', 'UNRATED', 'NOT RATED', 'TV-14'])))
imdb_info = imdb_info[imdb_mask]
imdb_info.filter('mpaa_rating NOT IN ["UNRATED", "NOT RATED", "TV-14]')
# Convert columns to usable data types
imdb_info['budget'] = imdb_info['budget'].apply(int)
imdb_info['opening'] = imdb_info['opening'].apply(int)
imdb_info['release'] = pd.to_datetime(imdb_info['release'].apply(lambda x: x.split('(')[0].strip()))
# Add new columns for plotting (financial info in millions)
imdb_info['budget_mil'] = imdb_info['budget']/1000000.
imdb_info['opening_mil'] = imdb_info['opening']/1000000.
# Change title ID column name to 'tconst' for consistency with other data tables
imdb_info['tconst'] = imdb_info['title_id']
imdb_info.drop('title_id', inplace=True, axis=1)
imdb_info.head()
Now we're down to about 750 movies. This'll give us a nice-sized dataset to work with (not too big to run the next step with Selenium, but a sufficient amount of data to build our model). Now we'll merge this DataFrame with the list of movie titles we have to get a list of unique cast members that were involved in these films.
# Merge with IMDB raw data
with open('my_data.pkl', 'rb') as picklefile:
titles = pickle.load(picklefile)
titles_all = imdb_info.merge(titles, on='tconst')
Now, in the titles_all DataFrame, we have a list of movie titles tied to their primary cast and crew members (labeled principalCast). What we really want to extract here is a list of unique actors and crew members for all of the movies of interest, but we will want to keep these actors tied to each movie for later joins and merges. We can accomplish this by looking only at the title IDs (tconst) and associated cast lists (principalCast), and expand this DataFrame to have a single row for each combination of title ID and name ID.
col_names = ['tconst', 'principalCast']
expanded_data = []
for idx, row in titles_all[col_names].iterrows():
for name in row['principalCast'].split(','):
expanded_data.append([row['tconst'], name.strip()])
expanded_data = pd.DataFrame(expanded_data, columns=['tconst', 'nconst'])
We now have a list of all of the actors we'll need to get more info on, as well as some record of how these actors are tied to each movie! This simple-looking DataFrame will prove to be extremely useful in the next steps, in which we'll scrape data from IMDB's STARmeter, and aggregate this data in a way that will help us build our model.
Using Selenium to scrape IMDB-Pro
To reiterate, the primary goal of this project is to discover how the popularity of a movie's primary cast members can be used to predict the hype surrounding a movie's opening weekend (i.e. Opening Box Office gross ticket sales). In order to do this, we need to find some metric to quantify cast popularity. Fortunately for us, IMDB already does this!

Through an IMDB Pro account, we can actually track any given actor's IMDB popularity by using the actor's STARmeter rank. This ranking, which is given on a weekly basis to every cast or crew member listed on IMDB, reflects how often a given cast member comes up in user searches. The IMDB website sums up the meaning of STARmeter rankings perfectly:
“Plain and simple, they represent what people are interested in, based not on small statistical samplings, but on the actual behavior of millions of IMDb users. Unlike the AFI 100 or Academy Awards, high rankings on STARmeter...do not necessarily mean that something is “good.” They do mean that there is a high level of public awareness and/or interest in the...person...”
This should give us a good metric to work with to quantify the cast popularity of any given film. Ideally, we'd be able to just scrape the current STARmeter rank for each actor, but since we are working with movies released as early as 2014, this won't give us a good idea of what the rankings were at or near the time of each movie's release. This makes our scraping process more challenging, since we will need to scrape not just a single number, but the time series data over the past 5 years.
This data is available to us through each webpage, but the actual values are tricky to extract using only a Scrapy spider like we used previously. The actual data is stored in a database which is filtered by the visualization itself. Here's a sample of the figure's SVG element:
<svg height="300" version="1.1" width="818" xmlns="http://www.w3.org/2000/svg" style="overflow: hidden; position: relative;">
<desc style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);">Created with Raphaël 2.1.0</desc>
<defs style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);">
<linearGradient id="22590-_FAFDFE:0-_0082C0:90" x1="0" y1="1" x2="6.123233995736766e-17" y2="0" gradientTransform="matrix(1,0,0,1,0,0)" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);">
<stop offset="0%" stop-color="#fafdfe" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></stop>
<stop offset="90%" stop-color="#0082c0" stop-opacity="0.5" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></stop>
</linearGradient>
</defs>
<image x="10" y="6" width="8" height="7" preserveAspectRatio="none" xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="https://images-na.ssl-images-amazon.com/images/G/01/IMDbPro/images/miniarrow_flat-343859503._CB514895051_.png" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></image>
<text x="22" y="10" text-anchor="start" font="11px Arial" stroke="none" fill="#797979" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); text-anchor: start; font-style: normal; font-variant: normal; font-weight: normal; font-stretch: normal; font-size: 11px; line-height: normal; font-family: Arial;">
<tspan style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);" dy="3.84375">Flat No Change in rank from Feb 10, 2013 - Feb 4, 2018</tspan>
</text>
.
.
.
<path fill="none" stroke="#00799e" d="M0,264.5L818,264.5" stroke-width="3" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
<circle cx="12" cy="43.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="72" cy="208.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="168" cy="187.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="660" cy="205.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="732" cy="210.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="768" cy="189.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="780" cy="125.5" r="3" fill="#e8e8e8" stroke="#999999" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="24" cy="136.5" r="3" fill="#ffd188" stroke="#f9ad00" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<circle cx="780" cy="125.5" r="3" fill="#ffd188" stroke="#f9ad00" stroke-width="1" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></circle>
<rect x="0" y="0" width="6" height="300" r="0" rx="0" ry="0" fill="#ffffff" stroke="#008000" stroke-width="0" opacity="0" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); opacity: 0;"></rect>
<rect x="6" y="0" width="12" height="300" r="0" rx="0" ry="0" fill="#ffffff" stroke="#008000" stroke-width="0" opacity="0" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); opacity: 0;"></rect>
<rect x="18" y="0" width="12" height="300" r="0" rx="0" ry="0" fill="#ffffff" stroke="#008000" stroke-width="0" opacity="0" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); opacity: 0;"></rect>
<rect x="30" y="0" width="12" height="300" r="0" rx="0" ry="0" fill="#ffffff" stroke="#008000" stroke-width="0" opacity="0" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); opacity: 0;"></rect>
<rect x="42" y="0" width="12" height="300" r="0" rx="0" ry="0" fill="#ffffff" stroke="#008000" stroke-width="0" opacity="0" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0); opacity: 0;"></rect>
.
.
.
</svg>A couple of things to note about this <svg> element, that will be useful in developing our scraping script:
The <rect> elements break the interactive chart into 1 ~ 4 week blocks.
The rectangles themselves do not inherently contain the data that we need to extract, but rather contain relative coordinates within the <svg> element
However, hovering over each of these blocks updates the text within the first <tspan> element (which is within the first <text> element). This is where we will be extracting our data.
To accomplish this, we can develop a script in Selenium which basically automates the process of opening each web page and hovering over each <rect> element in the <svg> figure. The script will also handle logging into the site at the beginning of the scraping process, since login is required to access the data.
Let's walk through the code.
def launch_selenium(names_list):
# Launch the web broswer and log in to IMDB Pro
# Returns driver object for use in scraping process
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
import os
import time
import SENSITIVE as SENS
# mv chrome driver from Downloads to Applications
chromedriver = "/Applications/chromedriver"
os.environ["webdriver.chrome.driver"] = chromedriver
url = 'https://pro-labs.imdb.com/name/' + names_list[0] + '/'
driver = webdriver.Chrome(chromedriver)
driver.get(url)
loginButton = driver.find_element_by_xpath('//a[@class="log_in"]')
loginButton.click()
time.sleep(.5)
loginButton = driver.find_element_by_xpath('//input[@id="auth-lwa-button"]')
loginButton.click()
time.sleep(.5)
username_form = driver.find_element_by_id("ap_email")
username_form.send_keys(SENS.username)
password_form=driver.find_element_by_id('ap_password')
password_form.send_keys(SENS.password)
password_form.send_keys(Keys.RETURN)
return driver
The function launch_selenium is used to launch the Selenium-driven web browser, log-in to my Amazon account (to gain access to IMDB-Pro's content), and navigate to the first webpage that I will be scraping, based on my list of cast and crew of interest. In general, navigating through the login menu consists of following a similar pattern.
button = driver.find_element_by_xpath('<xpath/to/button/tag')
button.click()
That is, we find the xpath to each element we want to select, give that object a name, and then click it. When we reach the form to enter username and password, we select these elements in a similar way, but use the object's "send_keys" method instead to fill in the text fields.
Once we've logged into the form, the next step is to actually extract the StarMETER time series data from each actor's page. This will involve hovering over every element and extracting a number that is updated within the visualization's SVG element. The picture below highlights which element we should hover over, and which element we should select.

The actual code for this is fairly straightforward, and consists of looping through the "rect" tags in the ranking graph, clicking each element (to simulate a hover), and pulling and parsing the "tspan" tag that contains the numbers we're interested in. The code looks something like this:
graph_div = driver.find_element_by_id('ranking_graph')
location = graph_div.find_elements_by_tag_name('rect')[1:]
name = (driver.find_elements_by_class_name('display-name')[1]
.find_element_by_tag_name('a')
.text)
star_meter_data = []
for i in range(1, len(location)+1):
loc = graph_div.find_elements_by_tag_name('rect')[i]
(driver.find_element_by_class_name('current_rank')
.find_element_by_tag_name('span')
.click())
try:
loc.click()
except:
time.sleep(0.5)
g = graph_div.find_elements_by_tag_name('tspan')[-2:]
dates = g[0].text.split('-')
start_date = datetime.datetime.strptime(dates[0].strip(),
'%b %d, %Y')
end_date = datetime.datetime.strptime(dates[1].strip(),
'%b %d, %Y')
star_meter = int(g[1].text.split(':')[-1]
.strip()
.replace(',',''))
star_meter_data.append([i, name_id,
name, start_date,
end_date, star_meter])One thing to note is that before clicking each "rect" element, I'm clicking outside of the ranking graph itself (second line of the for loop). Occasionally, hovering over a "rect" element will bring up a tooltip to show movies released during the selected time period in which the actor appeared. Moving from one "rect" element directly to the next would sometimes result in selecting the tooltip instead of the rect element, causing errors in the script's execution. To account for this, we click whitespace outside of the ranking graph to reset all tooltips, and then click back to the next "rect" element.
Finally, this operation is performed for every cast or crew member of interest for our dataset, and stored to a Pandas DataFrame. This scraping process takes a while, and I love me some pickles, so this DataFrame is also stored in a pickle file after scraping each actor. That way, I can pick up where I left off when I need to cancel the operation and give my laptop a much needed rest.
And that's it! We now have our StarMETER rankings stored in a pickle. Stay tuned for Part 2 of this tutorial, in which I'll walk through the process of pre-processing this data to train a linear model which will be used to predict opening weekend box office gross.
And as always, feel free to get in touch if you have any questions or suggestions for my process!